Outline
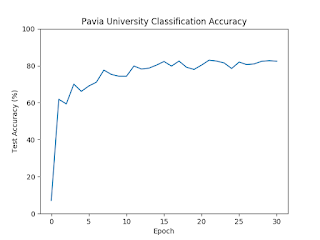
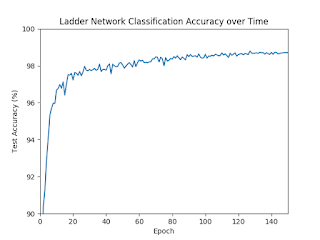
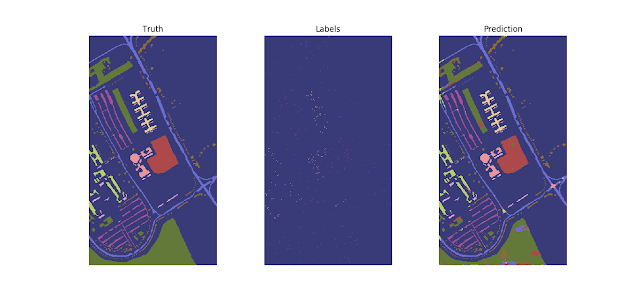
Motivation/Background: HSI classification What is HSI? Comparison to RGB The advantages of HSI over other kinds of data Instant, remote, nondestructive data collection Hundreds of data points per pixel What is classification? Introduce using toy data set, like CUB-200 Applications of HSI classification Cancer detection Art authentication Food quality analysis Remote sensing Urban development agricultural monitoring environmental assessment Problems faced High dimensionality Scarcity of labeled data Method: MCAE and Ladder Network Feature Extractors Baseline: PCA Inspiration: Autoencoder Our proposed method: MCAE Classifiers Baseline: SVM Inspiration: Neural network Our proposed method: Ladder network Results : State-of-the-art Comparison Comparison of MCAE against PCA and state-of-the-art Comparison of Ladder Network against SVM and state-of-the-art